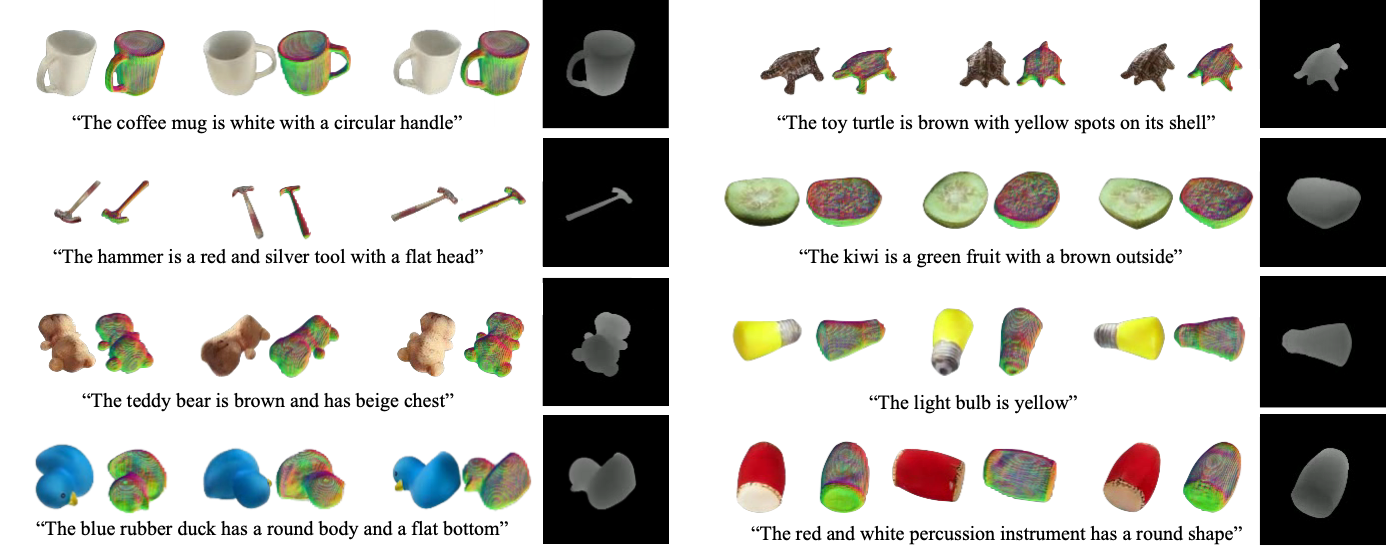
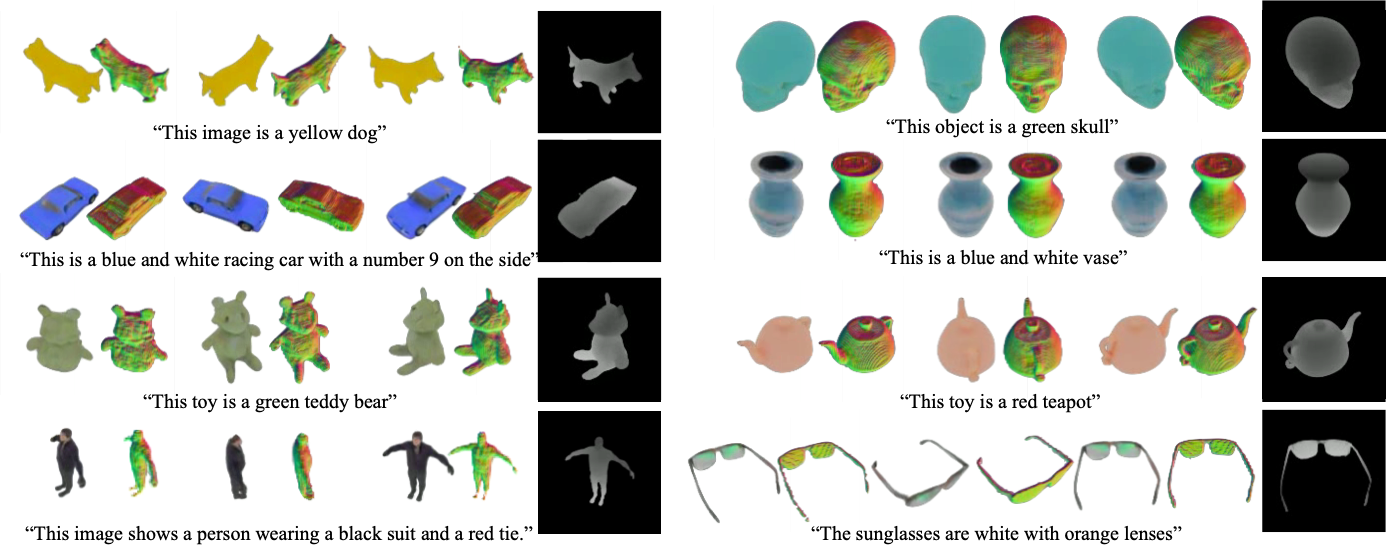
Our proposed two-stage framework: Stage 1 trains an autodecoder with two generative components, G1 and G2. It learns to assign each training set object a 1D embedding that is processed by G1 into a latent volumetric space. G2 decodes these volumes into larger radiance volumes suitable for rendering. Note that we are using only 2D supervision to train the autodecoder. In Stage 2, the autodecoder parameters are frozen. Latent volumes generated by G1 are then used to train the 3D denoising diffusion process. At inference time, G1 is not used, as the generated volume is randomly sampled, denoised, and then decoded by G2 for rendering.