3D generation on ImageNet
ICLR 2023 (Oral)
Abstract
Existing 3D-from-2D generators are typically designed for well-curated single-category datasets, where all the objects have (approximately) the same scale, 3D location and orientation, and the camera always points to the center of the scene. This makes them inapplicable to diverse, in-the-wild datasets of non-alignable scenes rendered from arbitrary camera poses. In this work, we develop a 3D generator with Generic Priors (3DGP): a 3D synthesis framework with more general assumptions about the training data, and show that it scales to very challenging datasets, like ImageNet. Our model is based on three new ideas. First, we incorporate an inaccurate off-the-shelf depth estimator into 3D GAN training via a special depth adaptation module to handle the imprecision. Then, we create a flexible camera model and a regularization strategy for it to learn its distribution parameters during training. Finally, we extend the recent ideas of transferring knowledge from pretrained classifiers into GANs for patch-wise trained models by employing a simple distillation-based technique on top of the discriminator. It achieves more stable training than the existing methods and speeds up the convergence by at least 40%. We explore our model on four datasets: SDIP Dogs 256x256, SDIP Elephants 256x256, LSUN Horses 256x256, and ImageNet 256x256 and demonstrate that 3DGP outperforms the recent state-of-the-art in terms of both texture and geometry quality.
Architecture overview

Left: our tri-plane-based generator. To synthesize an image, we first sample camera parameters from a prior distribution and pass them to the camera generator. This gives the posterior camera parameters, used to render an image and its depth map. The depth adaptor mitigates the distribution gap between the rendered and the predicted depth. Right: our discriminator receives a 4-channel color-depth pair as an input. A fake sample consists of the RGB image and its (adapted) depth map. A real sample consists of a real image and its estimated depth. Our two-headed discriminator predicts adversarial scores and image features for knowledge distillation.
Samples on ImageNet 256x256
Depth Adaptor ablation on SDIP Dogs 256x256
No Depth Adaptator: FID2k = 12.2
Adapting depth with 50% probability: FID2k = 9.25
Adapting depth with 100% probability: FID2k = 8.13
We use Depth Adaptor to adapt the depth rendered from generated 3D scenes before passing them into Discriminator. Otherwise, Generator will be forced to fit prediction artifacts of the LeReS depth estimator. And Depth Adaptor prevents its errors from leaking into the learned geometry. This helps to improve the image quality — for more more complex datasets (e.g., ImageNet), training diverges if we train without the depth adaptor.
Geometry comparison

Convergence speed with knowledge distillation
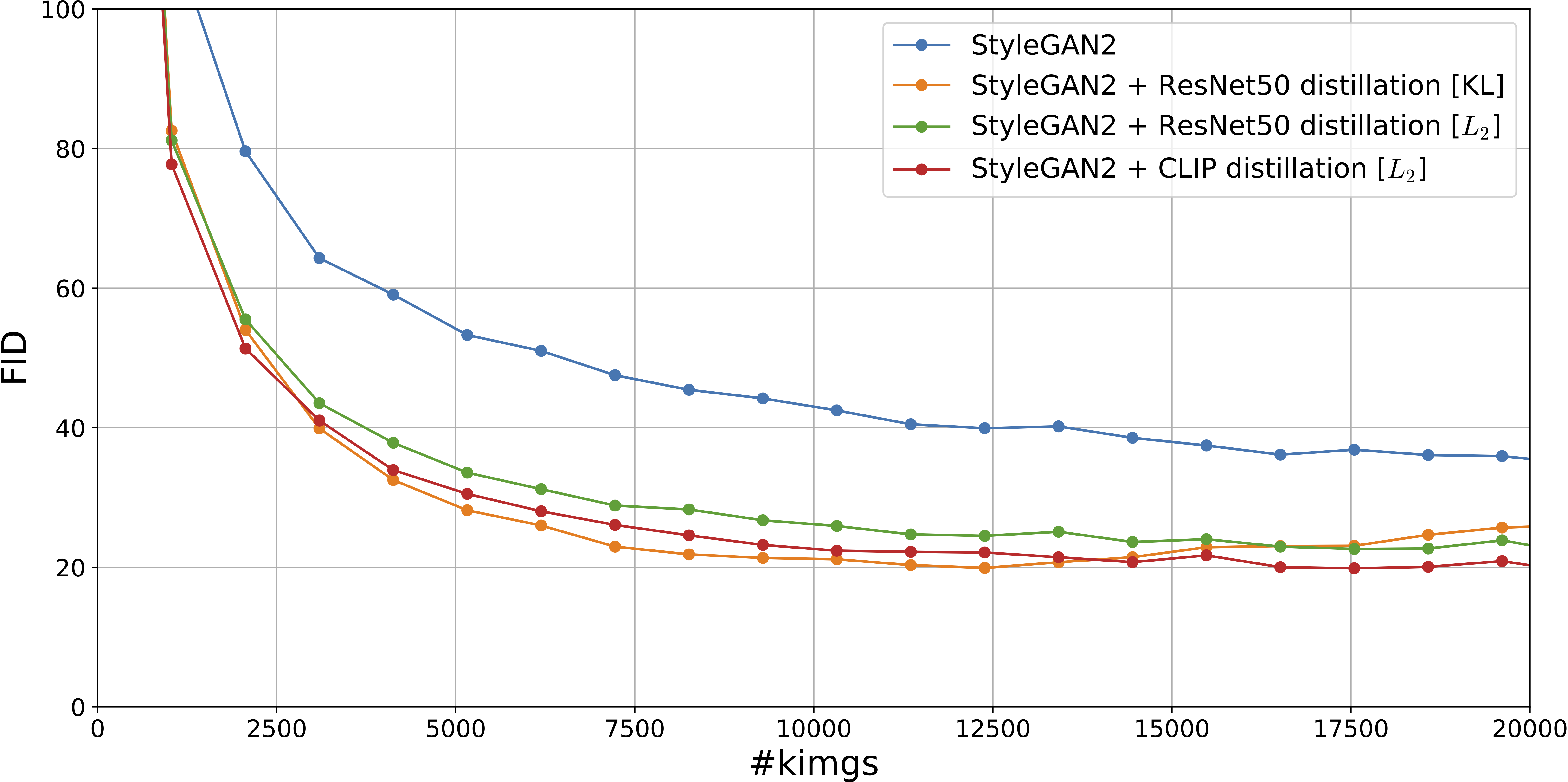
Convergence of StyleGAN2 (in terms FID vs the number of real images seen by Discriminator) on ImageNet 128x128 for different knowledge distillation strategies. We develop a general and efficient strategy of transferring external knowledge into the GAN model based on knowledge distillation. It consists in forcing the discriminator to predict features of a pre-trained ResNet50 model. This technique has just 1% of computational overhead compared to standard training, but allows to improve FID for both 2D and 3D generators by at least 40%. Compared to knowledge transfer through initialization (i.e., ProjectedGANs), it does not restrict the discriminator's architecture, and we can combine it with patch-wise training or using depth maps as the 4-th input channel.
Quantitative results
| Model | Synthesis type | FID ↓ | Inception Score ↑ | Training cost (A100 GPU days) ↓ |
|---|---|---|---|---|
| BigGAN | 2D | 8.7 | 142.3 | 60 |
| StyleGAN-XL | 2D | 2.3 | 265.1 | 163+ |
| ADM | 2D | 4.59 | 186.7 | 458 |
| EG3D | 3D-aware | 26.7 | 61.4 | 18.7 |
| + wide camera distribution | 3D-aware | 25.6 | 57.3 | 18.7 |
| VolumeGAN | 3D-aware | 77.68 | 19.56 | 15.17 |
| StyleNeRF | 3D-aware | 56.64 | 21.80 | 20.55 |
| StyleGAN-XL + 3DPhoto | 3D-aware | 116.9 | 9.47 | 165+ |
| EpiGRAF | 3D | 47.56 | 26.68 | 15.9 |
| + wide camera distribution | 3D | 58.17 | 20.36 | 15.9 |
| 3DGP (ours) | 3D | 19.71 | 124.8 | 28 |
Limitations and failure cases
😭 Background sticking and no 360° generation. Since we use . The contemporary VQ3D generator used Mip-NeRF-360's coordinates contraction to fit an onbounded scene into tri-planes' \([-1, 1]^3\) cube. We believe it could be help with background sticking. For 360 generation, one needs supervision for side-views, which could be obtained via DreamFusion-like guidance by a general-purpose text-to-image 2D diffusion model.
😬 Lower visual quality compared to 2D generators. Despite providing a more reasonable representation of the underlining scene, 3D generators still have a lower visual quality compared to 2D generators. Closing this gap is essential for a wide adaptation of 3D generators.
😢 Skewed geometry because of the relative depth. At the time of project development, there were no general-purpose metric depth estimators available, that's why we used LeReS, which is a relative depth estimator. This does not give good guidance since the recovered 3D shapes from a relative depth estimator are skewed. But recently, there started to appear general-purpose metric depth estimators (e.g., ZoeDepth).
😟 Camera generator does not learn fine-grained camera control. While our camera generator is conditioned on the class label, and, in theory, it should be able to perform fine-grained control over the class focal length distributions (which is natural since landscape panoramas and close-up view of a coffee mug typically have different focal lengths), we observed that it is doing this only for controlled experiments (e.g., on Megascans Food \(128^2\)). For ImageNet, we didn't observed that our Generator does not learn any fine-grained control over FoV. We attribute this problem to the implicit bias of the generator to produce large-FoV images due to tri-planes parametrization. Tri-planes define a limited volume box in space, and close-up renderings with large focal length would utilize fewer tri-plane features, hence using less generator’s capacity. This is why 3DGP attempts to perform modeling with larger field-of-view values.
😱 Flat geometry for some classes. Despite our best efforts to enable rich geometry guidance, we noticed that our tri-plane-based generator is still inherently biased towards producing flat shapes (which was also noticed by EG3D and GMPI).
😕 On ImageNet, we have low intra-category diversity (i.e., notorious GAN mode collapse). We observed that our Generator is biased towards producing low intra-class diversity. We attribute this to two reasons: 1) generating 3D is considerably more difficult than generating 2D and thus requires more capacity, but our Generator is relatively small even compared to 2D ImageNet generators; 2) it is more difficult for Discriminator to detect a mode collapse when the same shape is rendered from different camera positions and thus creating the effect of multiple different images. At the same time, we didn't observe any mode collapse issue on other datasets.
BibTeX
@inproceedings{3dgp,
title={3D generation on ImageNet},
author={Ivan Skorokhodov and Aliaksandr Siarohin and Yinghao Xu and Jian Ren and Hsin-Ying Lee and Peter Wonka and Sergey Tulyakov},
booktitle={International Conference on Learning Representations},
year={2023},
url={https://openreview.net/forum?id=U2WjB9xxZ9q}
}