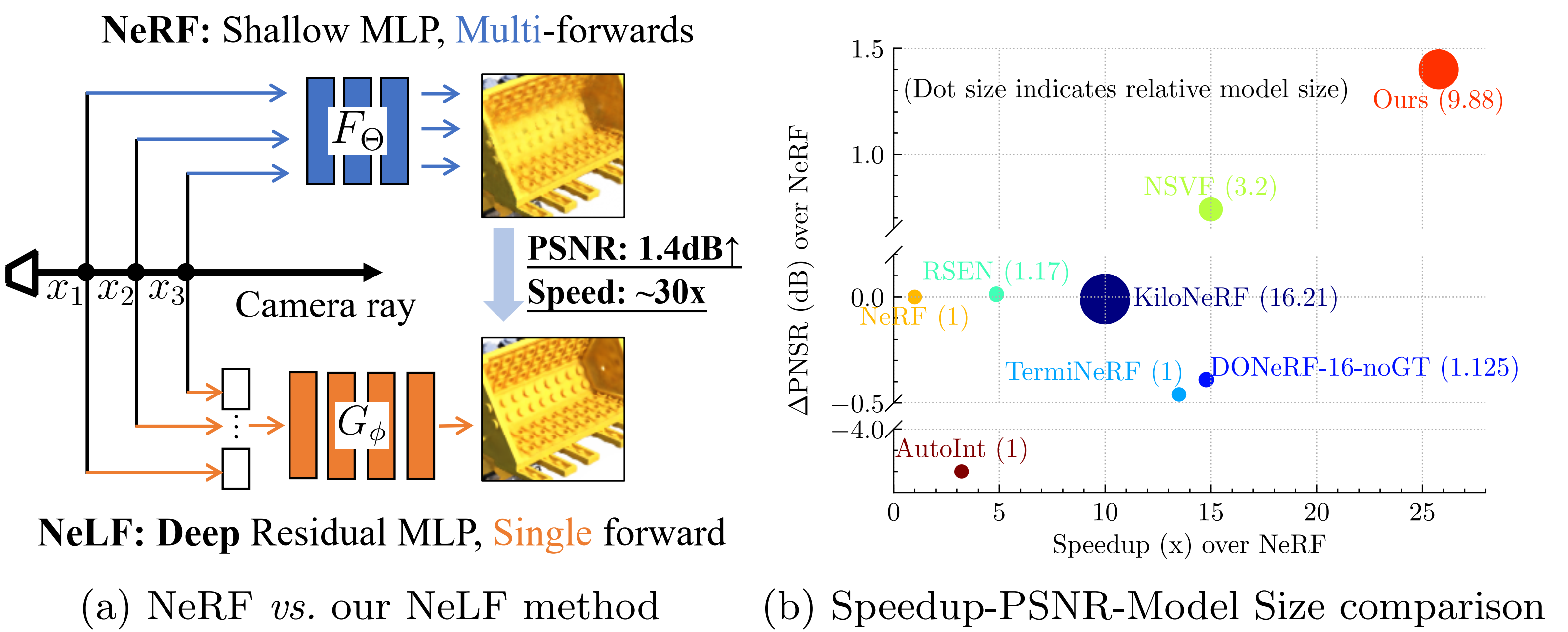
We present R2L, a deep (88-layer) residual MLP network that can represent the neural light field (NeLF) of
complex synthetic and real-world scenes. It is featured by compact representation size (~20MB storage size),
fast rendering speed (~30x speedup than NeRF), significantly improved visual quality (1.4dB boost than NeRF),
with no whistles and bells (no special data structure or parallelism required).
Abstract
Recent research explosion on Neural Radiance Field (NeRF) shows the encouraging potential to represent
complex scenes with neural networks. One major drawback of NeRF is its prohibitive inference time: Rendering
a single pixel requires querying the NeRF network hundreds of times. To resolve it, existing efforts mainly
attempt to reduce the number of required sampled points. However, the problem of iterative sampling still
exists. On the other hand, Neural Light Field (NeLF) presents a more straightforward representation over
NeRF in novel view synthesis -- the rendering of a pixel amounts to one single forward pass without
ray-marching. In this work, we present a deep residual MLP network (88 layers) to effectively learn the
light field. We show the key to successfully learning such a deep NeLF network is to have sufficient data,
for which we transfer the knowledge from a pre-trained NeRF model via data distillation. Extensive
experiments on both synthetic and real-world scenes show the merits of our method over other counterpart
algorithms. On the synthetic scenes, we achieve 26-35x FLOPs reduction (per camera ray) and 28-31x runtime
speedup, meanwhile delivering significantly better (1.4-2.8 dB average PSNR improvement) rendering quality
than NeRF without any customized implementation tricks.
1. Visual Comparison on NeRF Synthetic and Realistic Datasets
(You may pause the video to review the difference between NeRF and ours)
@inproceedings{wang2022r2l,
title={R2L: Distilling Neural Radiance Field to Neural Light Field for Efficient Novel View Synthesis},
author={Wang, Huan and Ren, Jian and Huang, Zeng and Olszewski, Kyle and Chai, Menglei and Fu, Yun and Tulyakov, Sergey},
booktitle={European Conference on Computer Vision},
year={2022}