SnapFusion: Text-to-Image Diffusion Model on Mobile Devices within Two Seconds
-
Yanyu Li
†
Snap Inc., Northeastern University -
Huan Wang
†
Snap Inc., Northeastern University -
Qing Jin
†
Snap Inc. -
Ju Hu
Snap Inc. -
Pavlo Chemerys
Snap Inc. -
Yun Fu
Northeastern Unviersity -
Yanzhi Wang
Northeastern Unviersity -
Sergey Tulyakov
Snap Inc. -
Jian Ren
†
Snap Inc.
NeurIPs 2023


Abstract
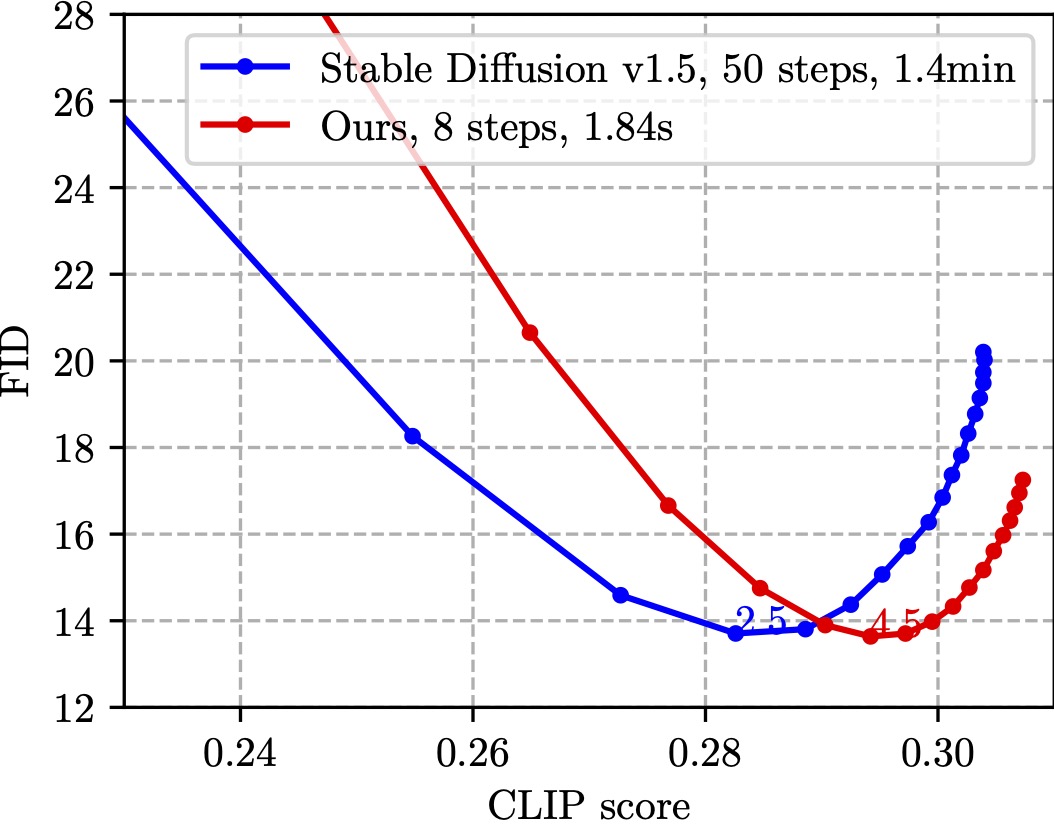
Text-to-image diffusion models can create stunning images from natural language descriptions that rival the work of professional artists and photographers. However, these models are large, with complex network architectures and tens of denoising iterations, making them computationally expensive and slow to run. As a result, high-end GPUs and cloud-based inference are required to run diffusion models at scale. This is costly and has privacy implications, especially when user data is sent to a third party. To overcome these challenges, we present a generic approach that, for the first time, unlocks running text-to-image diffusion models on mobile devices in less than 2 seconds. We achieve so by introducing efficient network architecture and improving step distillation. Specifically, we propose an efficient UNet by identifying the redundancy of the original model and reducing the computation of the image decoder via data distillation. Further, we enhance the step distillation by exploring training strategies and introducing regularization from classifier-free guidance. Our extensive experiments on MS-COCO show that our model with 8 denoising steps achieves better FID and CLIP scores than Stable Diffusion v1.5 with 50 steps. Our work democratizes content creation by bringing powerful text-to-image diffusion models to the hands of users.
On-Device Demo - Screen recorded version (inputting text accelerated)
On-Device Demo
Comparison w/ Stable Diffusion v1.5 on MS-COCO 2014 validation set (30K samples)
More Example Generated Images
