Motion Representations for Articulated Animation
CVPR 2021
-
Aliaksandr Siarohin
University of Trento -
Oliver Woodford
Snap Inc. -
Jian Ren
Snap Inc. -
Menglei Chai
Snap Inc. -
Sergey Tulyakov
Snap Inc.


Abstract
We propose novel motion representations for animating articulated objects consisting of distinct parts. In a completely unsupervised manner, our method identifies object parts, tracks them in a driving video, and infers their motions by considering their principal axes. In contrast to the previous keypoint-based works, our method extracts meaningful and consistent regions, describing locations, shape and pose. The regions correspond to semantically relevant and distinct object parts, that are more easily detected in frames of the driving video. To force decoupling of foreground from background, we model non-object related global motion with an additional affine transformation. To facilitate animation and prevent the leakage of the shape of the driving object, we disentangle shape and pose of objects in the region space. Our model1can animate a variety of objects, surpassing previous methods by a large margin on existing benchmarks. We present a challenging new benchmark with high-resolution "videos and show that the improvement is particularly pronounced when articulated objects are considered, reaching 96.6% user preference vs. the state of the art.
Video
Overview
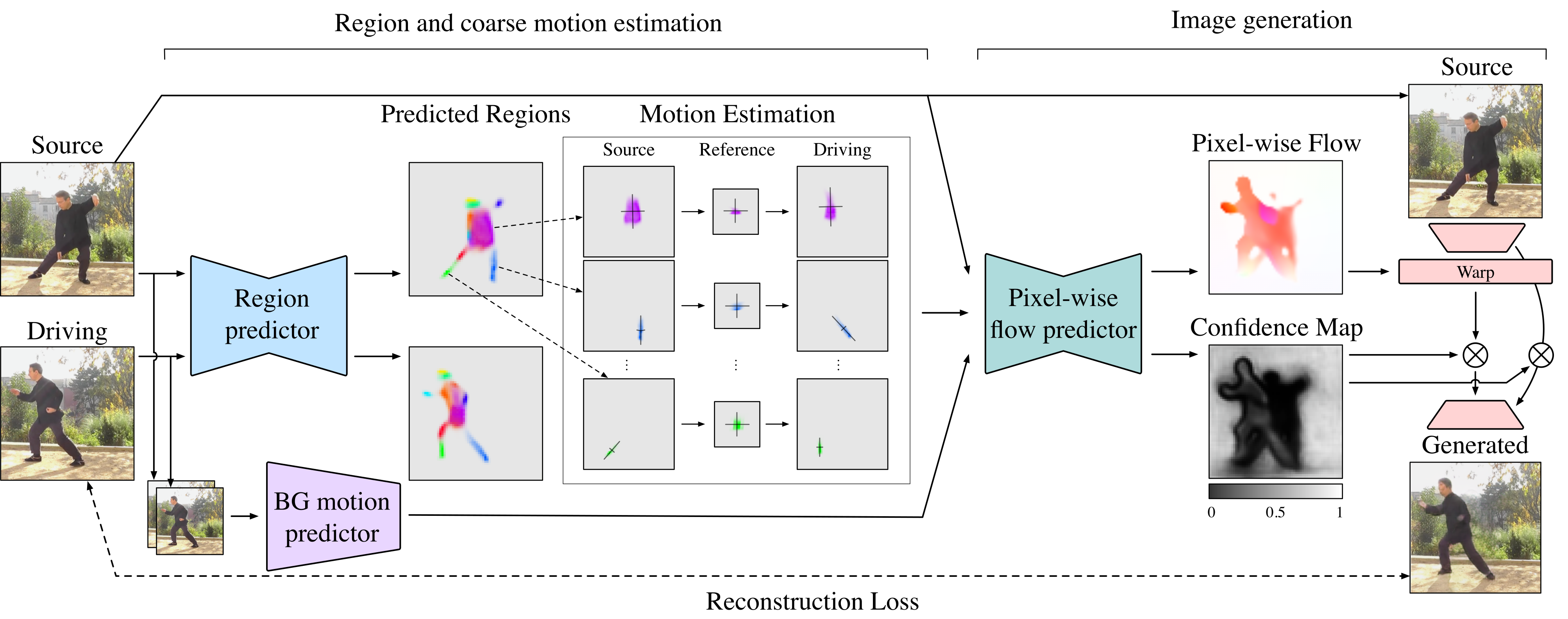
The region predictor returns heatmaps for each part in the source and the driving images. We then compute principal axes of each heatmap, to transform each region from the source to the driving frame through a whitened reference frame. Region and background transformations are combined by the pixel-wise flow prediction network. The target image is generated by warping the source image in the feature space using the pixel-wise flow, and inpainting newly introduced regions, as indicated by the confidence map.
Comparison on TedTalks
We compare our model with the First Order Motion Model (FOMM). Due to much improved motion representations our model shows substantially better results when articulated objects are animated. Our model generates impressive animations even when the poses of the source and the driving are significantly different. Each generated video has 384x384 resolution.
Modeling background motion
During training we assume affine background motion, predicted by the background motion predictor network.
At test time, this allows us to generate arbitrary affine motion in the background by passing the desired
warp field to the pixel-wise flow predictor. Below we show two examples with static background, up ↔ down
and left ↔ right motion as well as left ↔ right rotation.
Comparison on TaiChiHD
We further trained on TaiChiHD dataset and observe similar improvements as with TedTalks. The TaiChiHD
dataset is simpler as on average objects have similar shape and style.
Comparison on MGif dataset
Our model shows improvements on the MGif dataset. Local shape and identity details of each character
are better preserved compared with FOMM.
Animation via disentanglement
The standard or absolute animation involves copying the pixels of the source image to their locations in the driving video. This changes the identity of subjects. For example, when the source and the driving have different hair style, the standard animation visually enlarges the head, to match the head shape of the driving. Animation via disentanglement fixes such artifacts.
Ablation study for region estimation
Here we demonstrate the quality of learned regions and reconstruction quality for different ablation experiments. The first column is ground truth video, the second corresponds to "No pca or bg model" baseline (when affine transformations are predicted, no background modeling is used), the third column is the "No pca" baseline (when affine transformations are predicted, affine background motion is used), the fourth column is the "No bg" baseline (when affine transformations are measured, no background model is used), finally the fifth column corresponds to "Full method".
Qualitative region estimation results
We representative region estimation examples on the TaiChi dataset.
Co-part segmentation results
Finally we apply our method to unsupervised co-part segmentation.
Citation
The website template was borrowed from Michaël Gharbi.