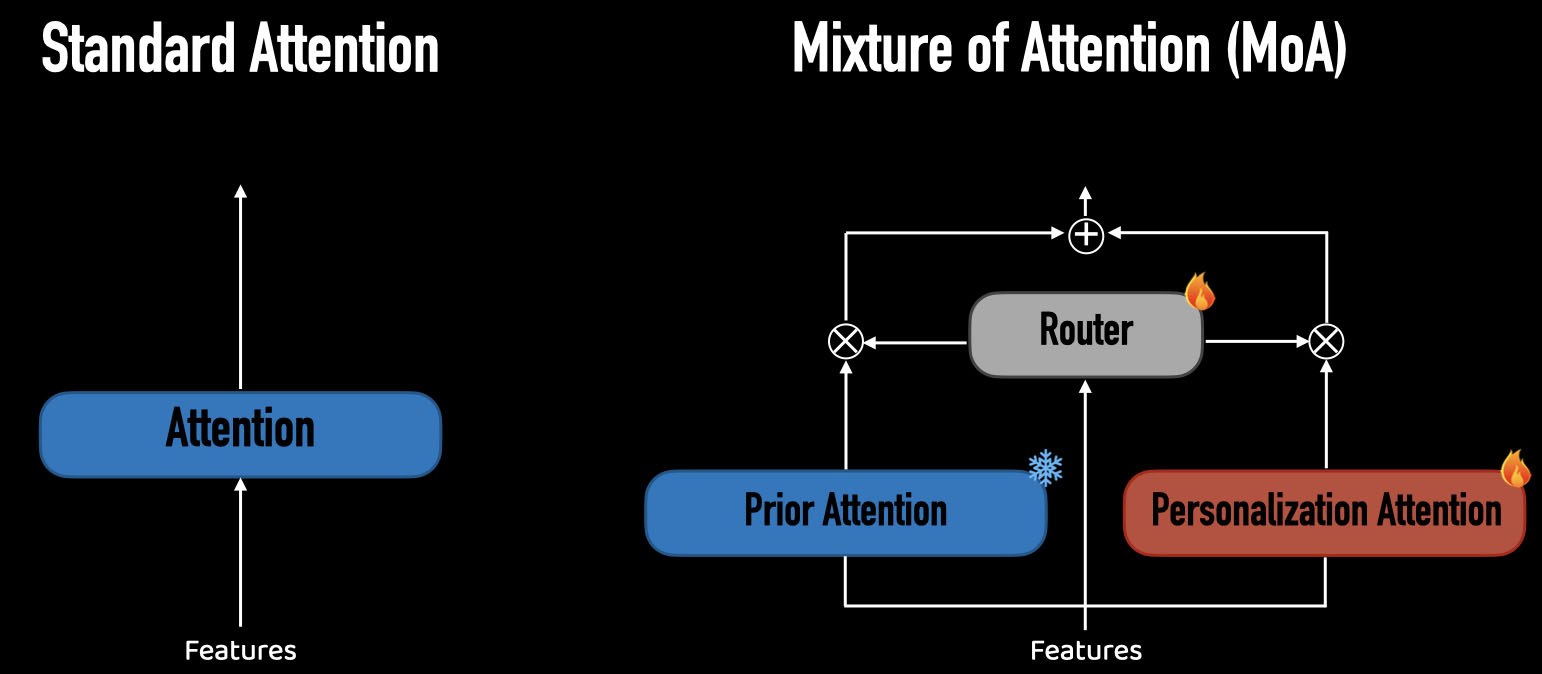
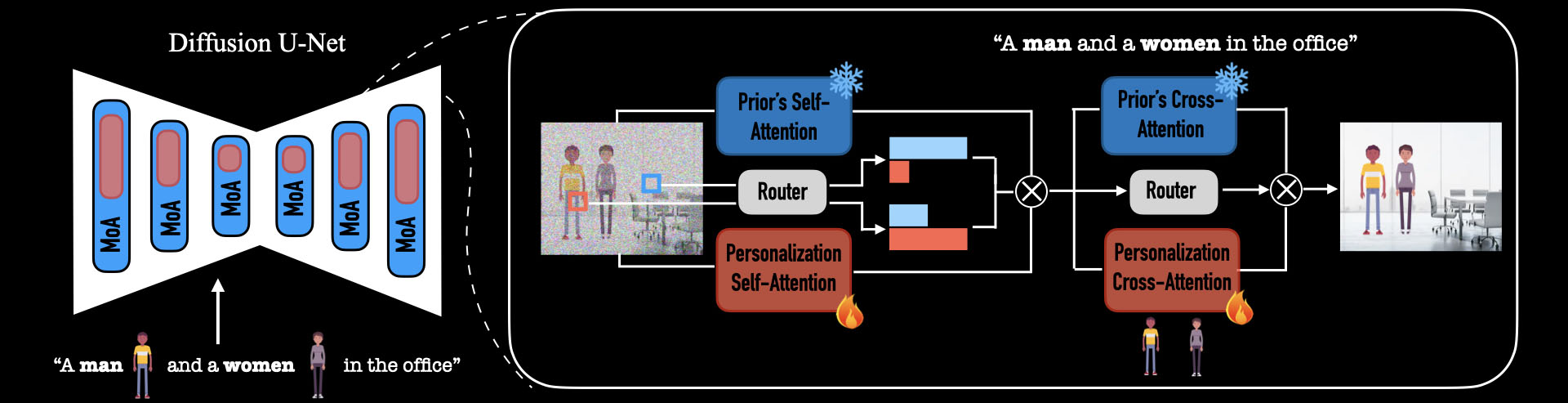
We introduce a new architecture for personalization of text-to-image diffusion models, coined
Mixture-of-Attention (MoA). Inspired by the Mixture-of-Experts mechanism utilized in large language models
(LLMs), MoA distributes the generation workload between two attention pathways: a personalized branch and
a non-personalized prior branch.
MoA is designed to retain the original model's prior by fixing its attention layers in the prior branch,
while minimally intervening in the generation process with the personalized branch that learns to embed
subjects in the layout and context generated by the prior branch.
A novel routing mechanism manages the distribution of pixels in each layer across these branches to
optimize the blend of personalized and generic content creation.
Once trained, MoA facilitates the creation of high-quality, personalized images featuring multiple
subjects with compositions and interactions as diverse as those generated by the original model.
Crucially, MoA enhances the distinction between the model's pre-existing capability and the newly
augmented personalized intervention, thereby offering a more disentangled subject-context control that was
previously unattainable.