Abstract
Contemporary models for generating images show remarkable quality and versatility. Swayed by these advantages, the research community repurposes them to generate videos. Since video content is highly redundant, we argue that naively bringing advances of image models to the video generation domain reduces motion fidelity, visual quality and impairs scalability. In this work, we build Snap Video a video-first model that systematically addresses these challenges. To do that, we first extend the EDM framework to take into account spatially and temporally redundant pixels and naturally support video generation. Second, we show that a U-Net—a workhorse behind image generation—scales poorly when generating videos, requiring significant computational overhead. Hence, we propose a new transformer-based architecture that trains 3.31 times faster than U-Nets (and is ~4.5 faster at inference). This allows us to efficiently train a text-to-video model with billions of parameters for the first time, reach state-of-the-art results on a number of benchmarks, and generate videos with substantially higher quality, temporal consistency, and motion complexity. The user studies showed that our model was favored by a large margin over the most recent methods.
The Snap Video Model
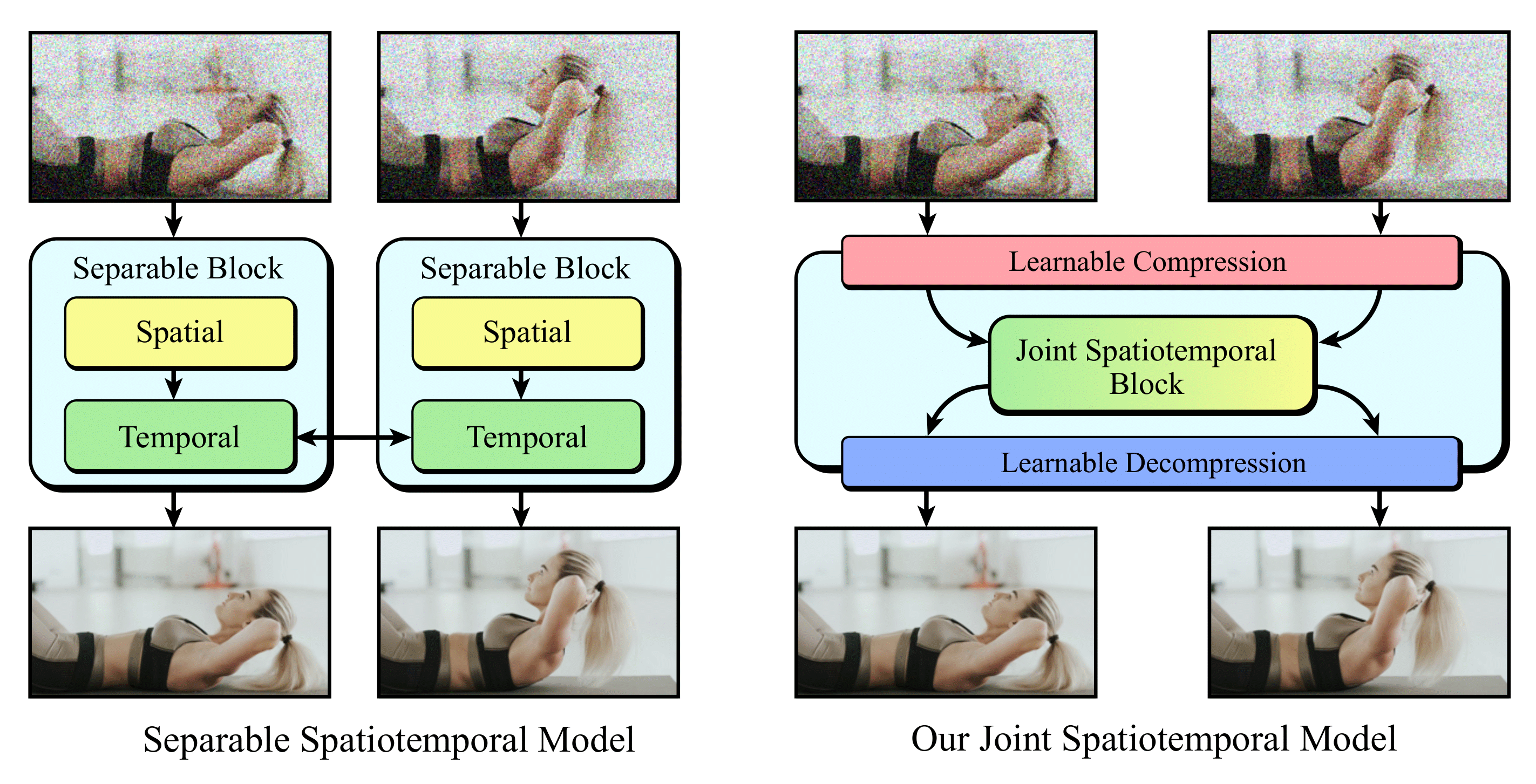
Computational Paradigms for Video
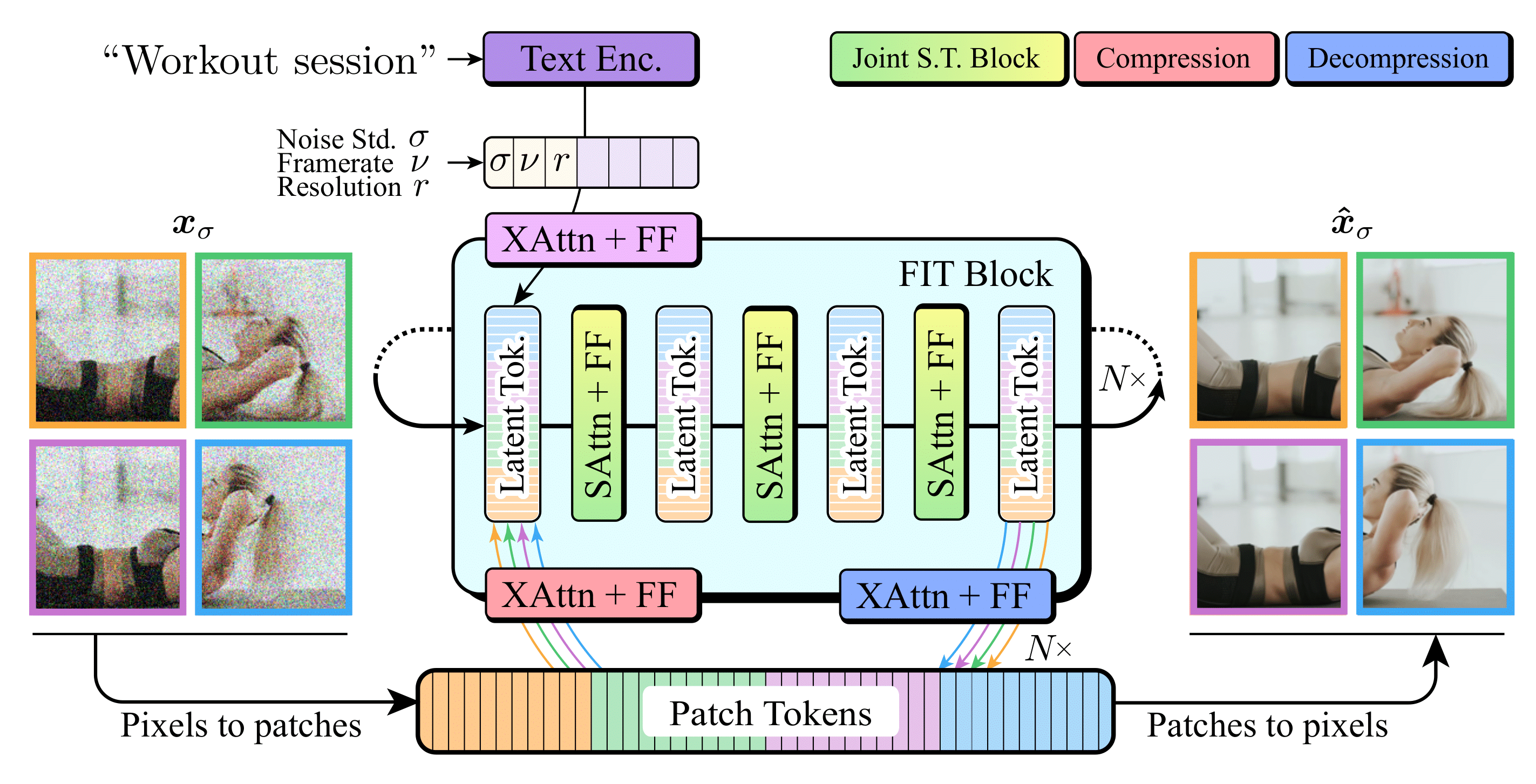
Snap Video FIT Architecture
The widely adopted U-Net architecture is required to fully processes each video frame. This increases computational overhead compared to purely text-to-image models, posing a very practical limit on model scalability. In addition, extending U-Net-based architectures to naturally support spatial and temporal dimensions requires volumetric attention operations, which have prohibitive computational demands.
Inspired by FITs, we propose to leverage redundant information between frames and introduce a scalable transformer architecture that treats spatial and temporal dimensions as a single, compressed, 1D latent vector. This highly compressed representation allows us to perform spatio-temporal computation jointly and enables modelling of complex motions.
Thanks to joint spatiotemporal video modeling, Snap Video can synthesize temporally coherent videos with large motion (left) while retaining the semantic control capabilities typical of large-scale text-to-video generators (right).
Hover the cursor on the video to reveal the prompt.
Acknowledgements
We would like to thank Oleksii Popov, Artem Sinitsyn, Anton Kuzmenko, Vitalii Kravchuk, Vadym Hrebennyk, Grygorii Kozhemiak, Tetiana Shcherbakova, Svitlana Harkusha, Oleksandr Yurchak, Andrii Buniakov, Maryna Marienko, Maksym Garkusha, Brett Krong, Anastasiia Bondarchuk for their help in the realization of video presentations, stories and graphical assets, Colin Eles, Dhritiman Sagar, Vitalii Osykov, Eric Hu for their supporting technical activities, Maryna Diakonova for her assistance with annotation tasks.