Taming Data and Transformers for Audio Generation
International Journal of Computer Vision (IJCV)

 Snap Research
Snap Research
International Journal of Computer Vision (IJCV)
Snap Research
Generating ambient sounds is a challenging task due to data scarcity and often insufficient caption quality, making it difficult to employ large-scale generative models for the task. In this work, we tackle this problem by introducing two new models. First, we propose AutoCap , a high-quality and efficient automatic audio captioning model. By using a compact audio representation and leveraging audio metadata, AutoCap substantially enhances caption quality, reaching a CIDEr score of 83.2, marking a 3.2% improvement from the best available captioning model at four times faster inference speed. Second, we propose GenAu, a scalable transformer-based audio generation architecture that we scale up to 1.25B parameters. Using AutoCap to generate caption clips from existing audio datasets, we demonstrate the benefits of data scaling with synthetic captions as well as model size scaling. When compared to state-of-the-art audio generators trained at similar size and data scale, GenAu obtains significant improvements of 4.7% in FAD score, 22.7% in IS, and 13.5% in CLAP score, indicating significantly improved quality of generated audio compared to previous works. Moreover, we propose an efficient and scalable pipeline for collecting audio datasets, enabling us to compile 57M ambient audio clips, forming AutoReCap-XL, the largest available audio-text dataset, at 90 times the scale of existing ones. Our code, model checkpoints, and dataset are publicly available
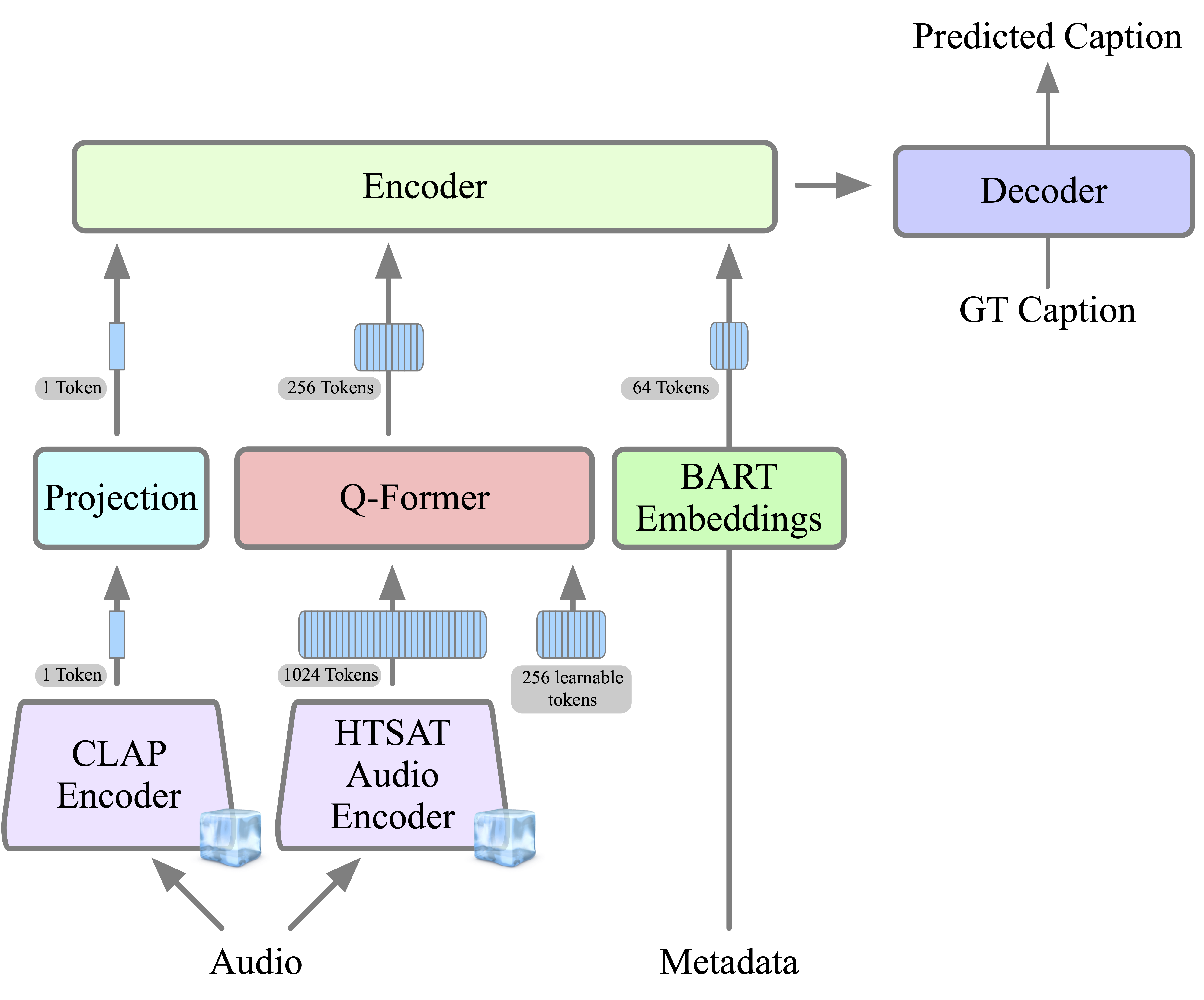
AutoCap: We employ frozen CLAP and HTSAT audio encoders to produce the audio representation. We then compact this representation into 4x less tokens using a Q-Former module. This enhances the efficieny of the captioning model and aligning the audio representation with the language representation of a pretrained BART encoder-decoder model that aggregates these tokens along with tokens extected from useful metadata to produce the output caption.
GenAu: We use a frozen audio 1D-VAE to produce a sequence of latents from a Mel-Spectrogram representation. Based on the FIT architecture, these latents are patchified and divided into groups which processed by local attention layers. The read and write operations are implemented as cross attention layers that transfer information between input latents and learnable latent tokens. Finally, global attention layers process latent tokens with attention spanning over all groups of latent tokens, enabling global communication.

AutoReCap: We propose an efficient and scalable pipeline for collecting audio datasets, enabling us to compile 57M ambient audio clips, forming AutoReCap-XL, the largest available audio-text dataset, at 90 times the scale of existing ones. Our data data collection approach
leverages existing automatic video transcription to identify segments with ambient sounds. We then use our proposed captioning method AutoCap to caption the identified segments and exclude speech and music audio clips based on keyword search.
Please refer to the Dataset page for more samples and GitHub page for instructions on downloading the dataset!
Taming Data and Transformers for Audio Generation (2.1 MB)
Bibtex: @article{haji2026taming, |