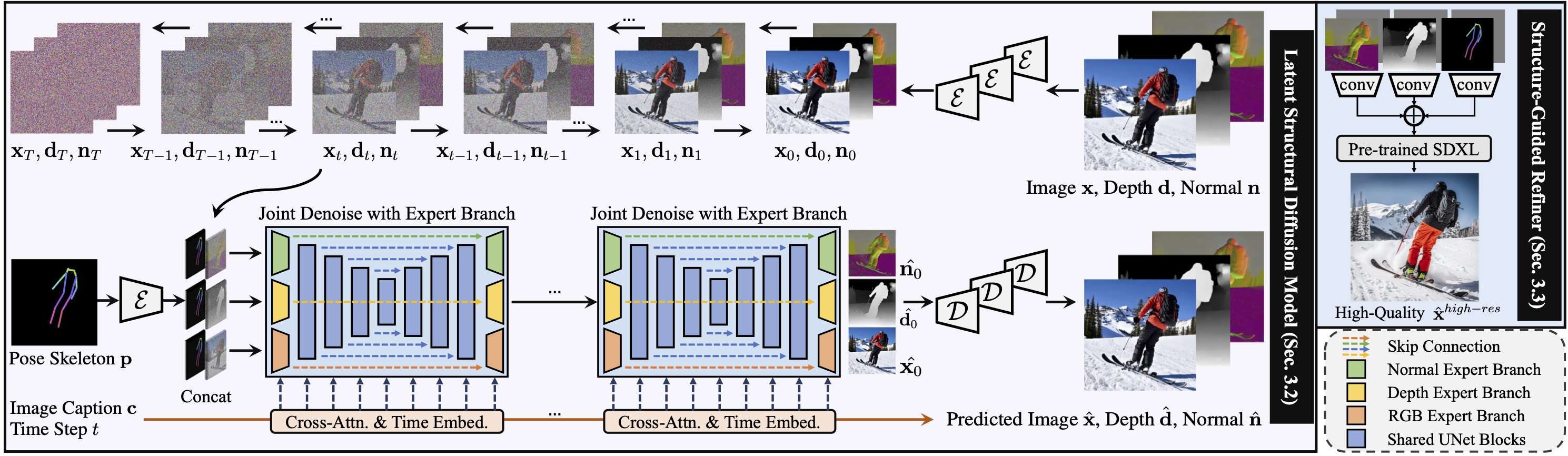
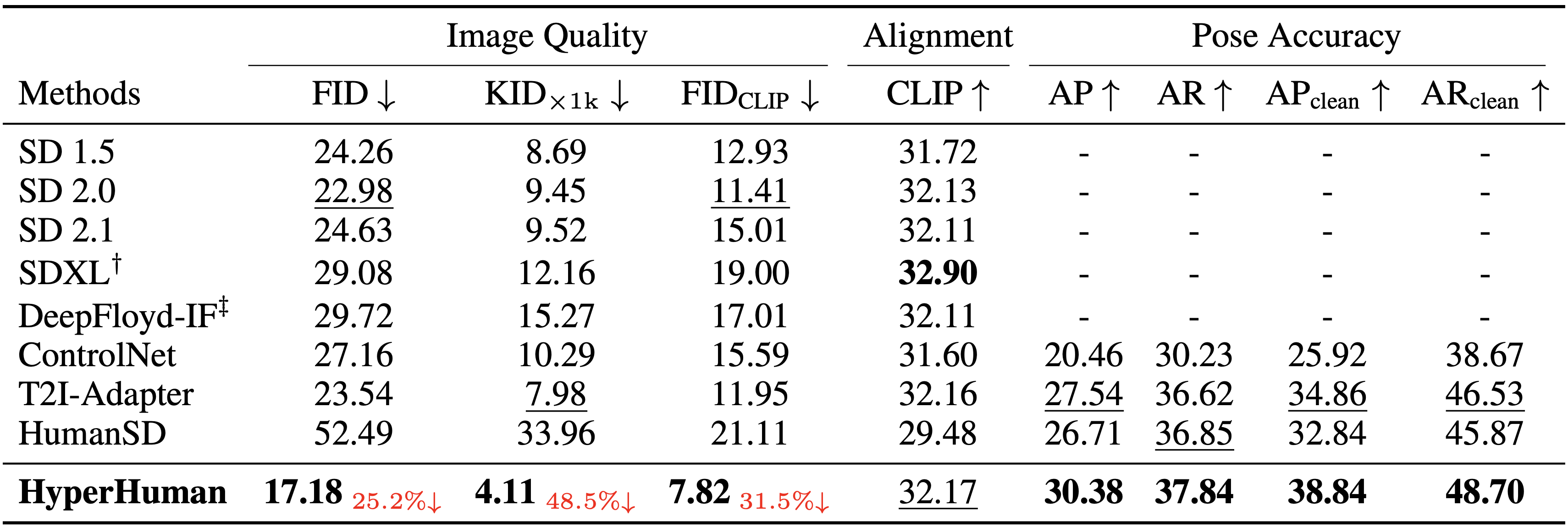
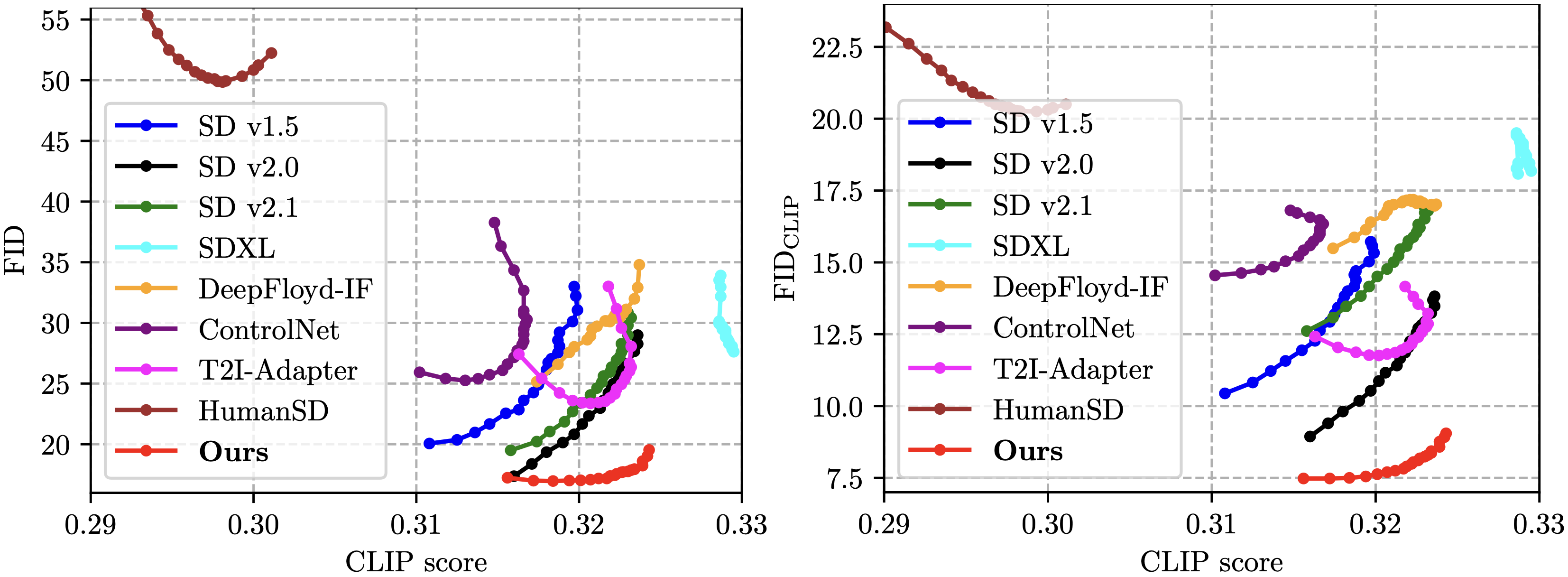
HyperHuman: Hyper-Realistic Human Generation with Latent Structural Diffusion
1Snap Inc.
2CUHK
3HKU
4NTU

A baby girl with beautiful blue eyes standing next to a brown teddy bear.

A little girl with wavy hair and smile holding a teddy bear.

A man and woman seated at a table in a restaurant.

A cow laying on the grass behind a man holding a cup of coffee.

A young kid stands before a birthday cake decorated with captain America.

A man who is sitting in a bus looking away from the window.

A man in a red shirt is holding a skate board up over his head.

Two men who are sitting next to each other with a large pizza in front of them.

Two children carry an enormous stuffed teddy bear.

The upper half of a man posing for a photograph wearing a suit with a blue tie and matching pocket corner.

An older man is wearing a funny hat in his dining room.

Young man on top of a snowboard wearing maroon jacket.

Man sitting on brick covered ground, appearing dirty and tired.

A man wearing a purple neck tie and glasses while sitting in a car.

A man standing on grassy area next to trees.

A girl with blue hair is taking a self portrait.

A man wearing a helmet is sitting on his blue motorcycle.

A person dressed up taking a picture at a street with his fist up.